Turn needle valve (high speed) clockwise until it closes. Do not force, stop when screw closes. Now open needle valve 1 1/8 turns counterclockwise. This will permit engine to start and final adjustment can be made after engine warms up.
– FINAL ADJUSTMENT Place governor speed control in “FAST” position (that means open throttle all the way). Turn needle valve in clockwise until engine slows(lean). Then turn it out counterclockwise past the smooth operating point(rich). Now turn the needle valve to the midpoint between lean and rich. Next adjust the idle mixture. Rotate the throttle counterclockwise and hold against stop.Adjust idle speed adjusting screw to obtain 1750 RPM. Holding throttle against the stop turn idle valve in (lean) and out (rich). Set at mid point between lean and rich. Re-check idle RPM. Release throttle. If engine will not accelerate properly, the carburetor should be re-adjusted, usually to a slightly richer mixture.
The one item of interest that I have seen lately is a case study that speaks of high oxidative stress/glutathione ratio being an indicator of poor outcome with Covid-19. This study speaks to the possibility of using NAC N-acetyl-cystine, a precursor to glutathione, it being comprised of NAC and glutamate, as a supplement to reduce oxidative stress. It also can shorten the bonds that form clotting via von Willebrand factor (VWF), a blood glycoprotein involved in hemostasis. There is a question of why not supplement with glutathione directly, as well. I know that asparagus and kombucha both contain high amounts, for food at least, of glutathione. Not sure if the body will uptake it directly or if it gets broken into the 3 amino acids and gets built back up again. With NAC/glutathione, it is also interesting to note as thrombosis has been associated with Covid-19 and of course this is a type of clotting. In my personal opinion, the links in the logic of the science with this playing a role seems plausible in theory. More studies would be required to confirm but, it is nice to see all of the effort being poured into the issue. I started down this path of research via the following videos…
Recently I posted a comment to this video below. What got me to post this comment besides the video itself was the censorship of Coronavirus videos on YouTube created by Dr. Seheult which thankfully are still all available on MedCram. Also I recently heard of censorship on Facebook as well.
Comment to Video
Personally I believe that major problems with social media as it is are privacy, censorship and machine learning curation of content that may include unintentional bias. I understand with machine learning many times the bias is accidental and purely based on the data going in to create the model. Another subtle potential issue with social media is manipulation, as in the manipulation of human behavior in order to create a situation in which they can be motivated to act in ways that are good and thereby profitable for the entity that owns the platform but not in a healthy behavior pattern for the individual in the long run. In my opinion humans can be subtly gamed with stimulating content curated by the platforms that can do things from as simple as encouraging more use of it to something along the lines of gently reforming a set of values that could sway a populations way of thinking over time. All institutions are capable of doing this but, social media being a unique personalized experience certainly has more power in this regard. It can be both your best friend and worst enemy. To shift forward into a new and more equitable model, in my opinion a good idea would be to redirect the funds that go from the government to the companies that run the social media platforms and fund programs at research universities to foster the development of alternative social media platforms. This would include any fines that would become levied on the social media companies for violations of the laws that will be written as a result of this executive order. The idea is to foster the development of alternative platforms that allow for a public commons on the Internet that is ideally along the lines of a self organizing system. Preferably it would not be under the control of any single entity and have transparency as far as the technology is concerned so there are no tricks up it’s sleeve, such as privacy concerns, censorship issues and unintended model/algorithm biases and unintentional human behavior modification. A model for this would be along the lines of what has been done with academic scientific research, open source software or other media such as Wikipedia, which by the nature of having many eyes on it becomes self adjusting to the needs and wants of the users, with the mechanism that achieves the results in plain sight. No doubt given enough funding and some bright minds on the task this could become a reality as the current technology required to achieve this goal is readily available.
Very informative series of videos. All of them dealing with Covid-19 to date, Dr. Seheult releases these update videos regularly. He is actively treating Covid-19 patients, from what I remember he is an internist and with pulmonary and sleep specialties. Below is a sampling of the videos that I found interesting, mostly centered on prevention and treatment. Covering new approaches such as Remdesivir and Choloquine. Supplements are also covered for general health and use for helping the bodies immune system. Plus some general information on how viruses work, which I had long forgotten about over the years. Some of the ideas in the videos are fairly unique, such as the importance of sleep for boosting the immune system and the positive effects of forest bathing.
UPDATE: There has been some censorship of Coronavirus videos on YouTube created by Dr. Seheult which thankfully are still all available on MedCram
Mail on the command line. This was once a thing that was used much more often. When I was in college in the 1990’s it was one of the easiest ways to get mail when on campus and off. It was taught to technical and non-technical people alike as part of orientation and you were given written instructions right at registration time. Instructions came along with the email account that they made up for you using a student id number followed by @binghamton.edu. In fact, finally in the last year I was there they got rid of this cumbersome email and started allowing users to have email with their real names.
Getting to mail back then from the command line involved logging into your Unix account from one of the many terminals spread throughout the campus. Or using the insecure but, OK at the time rlogin, remotely via dialup. Then you could either use mail or pine which was a bit more sophisticated as it was based off the pico editor, of which the popular nano editor is a derivative. It at least has somewhat of an interface that accepts up and down arrow movement and displays the shortcuts on the bottom. The standard mail program is a bit like vi, spartan but still useful.
Having access to mail locally on the command line is useful when you might be running CRON tasks or any other automated scripts that call other code as it allows you to get notified of when they have run and most importantly if they have had errors.
The other alternative is to set up ssmtp and have mail sent out of the local machine using SMTP from another established account. Of course you can also set up a full blown mail server but, that can be overkill if you are just monitoring what is happening on a few machines that you regularly log in to.
Setting up Local Mail
Below is a great Github post on how to set up local mail on a Linux Machine. I followed it and added a variation to get local mail running using the command line mail program.
It works great. I really liked the instructions, very easy to set up. I was glad I found this as, I thought it might be tricky and with these instructions it was a few minutes on each machine.
For use with mail the program, it might not be necessary to have a local host.com in the host file. I have not tested this.
I followed the tutorial up to and including the step of restarting postfix.
Then I installed mail instead of Thunderbird.
On the server, which only has a CLI, I wound up using mail instead of T-bird, installed via sudo apt-get install mailutils
It can be tested by sending a message to yourself by using… mail -s “test” (your user name)@localhost
Hit enter when in the screen to bypass CC , type something and end by using Ctrl D.
Then enter the command
mail
…and you should see the email. Hit enter at the? prompt and the message is presented.
Enter q to quit.
Another test message can be sent to test if a message to any address gets sent to you. As long as the domain is local host it will work and catch it. Other domains will fall and send you an email from the system reporting the email as undeliverable.
It works great to get the CRON messages on the machine.
Just type mail and you get a CLI email list. mail basics are, q to quit, m to compose, enter and spacebar to move through messages. Entering question mark ?, brings up command help.
Desktop Install
One gotcha that caught me is that I already had T-bird installed and therefore it had a default SMTP server already. For me this required what I would call step 6A to add a local STMP server. 6A. In the pane above “Account Actions” scroll, using the bar to the bottom “Outgoing Server (SMTP)”.
Click Add
For description I wrote Local SMTP
Server Name: localhost
Port: 25
Username : (the user name)@localhost
Authentication Method: Password, transmitted insecurely
Connection Security: None
Then I went back into the account settings for the mail set up in step 6 and set the Outgoing Server (SMTP) to the Local SMTP
Host File Aliases
Also in /etc/hosts you can put in localhost.com as a alias and it works fine, like this… 127.0.0.1 localhost localhost.com
This is the way to put in aliases in a host file, for example you can have the machine name and then a shortcut to it if you have it set to a static IP. This way you can just type server to SSH to it and use that as a short name wherever you want to in scripts and etc.
This post is an addition to the series on DMAC algorithm trading, which is simple algo trading example. I was wondering now that the S&P500 and etc, legacy market has dropped out of it’s long bull run, how would Bitcoin gains compare against the stock market?
The plan: Comparing Bitcoin (BTC) gains from January 1,2010 to December 31,2019 against the bottom for stocks on March 9, 2009 to Feb 19,2020, the 400% bull run for the S&P 500. But, for some reason the Yahoo data for Bitcoin is only going back to 2014-09-16. So we are basically getting a bit short changed here on BTC and giving the S&P a long head start for nearly 5 years. (I am sure at one point in the past, I think this used to work and go back all the way to 2010 but Yahoo must have cutoff the data since I first tried this code.)
So with 5 years head start for S&P
S&P500 4x gain across history shown in the above chart 03-09-2009 to 2-19-2020
BTC 16.96x gain from 9-16-2014 to 2-19-2020
Now for a true side by side comparison
S&P 500 on 9-16-2014 closed at 1998.98
S&P 500 on 2-19-2020 closed at 3386.15
S&P 500 gain 1.69x from 9-16-2014 to 2-19-2020
So Bitcoin beats the S&P using by and hold across the same time frame by 10x.
Buy and Hold -v- DMAC Algo Trading on BTC
OK, now what about BTC HODL (Buy and Hold) gains versus optimized DMAC algorithm trading from 9-16-2014 to 2-19-2020?
HODL Gains: 16.96393901373665
Algo gains for a 1 day short and 4 day long average. This is wicked tight and it will trade like mad, so in real life, the transaction fees and slippage would eat away at this number after 10 years.
Short AVG,Long AVG,Best Bank 1 4 2244962.564086914 which is 22.4x
which is 22.4x gains. But, with fees/slippage and HODL at ~17x , HODL is really great. Beats the 4x or 1.69x depending on the time frame of the S&P 500!
It could do better
This is a simple algorithm, one of the simplest ones that can be thought of. Also, remember that the algorithm only tuned once across the entire time period. If the time period was cut up into smaller periods and the algorithm learned the market as it changed over time instead of trying to get a best fit across 5 years it would have produced more gains. The example the initial post which has it trade from Jan 1 to Dec 31 of 2019 shows in making 900K alone in one year. So an algorithm that could in theory re-optimize periodically as the market conditions change would easily beat the results of this simple algorithm. The best thing that I can think of would be a machine learning algorithm that would use differential evolution to change the parameters as time goes on. It would learn on an ensemble of random sections of random lengths of data from the past and tune the algorithm’s parameters based on learning from the data ensembles. That is just one way that comes to mind.
But, at the end of the day this is just an example. It is not always possible to predict future results from past data. It is also well known and Covid-19, The Great Recession and Black Monday in 1987 serve as examples, there will be price shocks that can upend any model in practice. The statistics of price action do not fall neatly under a bell curve but have fat tails that lead to excursions far away from the mean on occasion. One only has to look to history for this lesson and one example is the firm Long-Term Capital Management (LTCM) led by a brilliant team of folks including Nobel prize winners Merton and Scholes, two out of the men that invented the Black-Scholes option pricing formula. Fischer Black, the other man was not alive at the time that the prize was awarded. Some credit for the formula rests with Ed Thorp as well, at least a way in the backstory. Ed Thorp had basically the same kind of formula running on convertible bonds, not a far jump to options pricing. This is all outlined in the great book The Quants by Scott Patterson. Quants was one of the seeds that led me to pursue trading, specifically algorithmic trading a few years after I read it.
Lessons To Be Learned
So there were brilliant guys were at the heart of LTCM but, due to high leverage and a divergence of their models from reality when the Russian government defaulted on their debt, the firm crashed and burned financially. It happened fast as they and others holding similar positions in the market all simultaneously unwound those positions. LTCM was stuck holding a lot of positions trying to offload into a market without many buyers, low liquidity, and the worst part of it, being leveraged heavily 30-40:1 was the real problem. They were effectively running backwards selling off, what normally one would not want to be forced to sell off, being highly leveraged it quickly ran out of margin and went effectively bankrupt. The pieces of LTCM were bought up by 13 banks and this averted a disaster that could have been equal to 2008 if the banks had not carved up the LTCM carcass among themselves. It could have easily had a domino effect on the rest of the banks and the global market much like what happened in 2008. LTCM as brilliant as it began, ended as a good lesson for the future, if only heeded and rocked the markets for a while and the shock cascaded. Then the lesson seems to get lost in general, although I imagine some took it to heart, in general history repeated itself about a decade later in terms of the next financial crisis which was the same thing only an order of magnitude larger. 2008 was not containable by some short term heroics between the Fed and 13 banks as in the case of LTCM.
Speculation in stocks will never disappear. It isn’t desirable that it should. It cannot be checked by warnings as to its dangers. You cannot prevent people from guessing wrong no matter how able or how experienced they may be. Carefully laid plans will miscarry because the unexpected and even the unexpectable will happen. Disaster may come from a convulsion of nature or from the weather, from your own greed or from some man’s vanity; from fear or from uncontrolled hope. – Reminiscences of a Stock Operator
This post is a trading resource dump on books for trading
I have some good books in the list. The ones that cover the psychological aspects of trading are worth the time to read if you have gotten past the basics of trading. It helps if you have traded a little at least to have some hands on experience with it. Best to start out with a few hundred dollars and build up the account as you get the hang of trading. Adding to the account slowly. I wish I had read these books in the beginning, just when I was trying the first half dozen trades, at the same time that I was learning about the technical aspects of trading.
This book is a good reference book. It compiles a lot of information that is in the public domain, mostly via Wikipedia in one place. At the end of each chapter there are good notes, references and further reading. It is good to have this on hand when you want to look something up quick or for beginners to get an overview of technical analysis.
In the Markets: Confessions of a Samurai Trader Edward Alan Toppel
Worth a read, especially for anyone that has been exposed to Asian culture. It still makes sense if you’re not familiar with the culture but, if you are it’s going to be a deeper read.
Very good, Elder Alexander is a Psychologist turned trader. He is also the inventor of the Triple Screen Trading System, which is outlined in the book.
Reminiscences of a Stock Operator Book by Edwin Lefèvre Zen
There is nothing like losing all you have in the world for teaching you what not to do. And when you know what not to do in order not to lose money, you begin to learn what to do in order to win. Did you get that? You begin to learn!
Very good, a must read! This book is supposedly handed out to new employees at Goldman Sachs to read as a first assignment. I can see why, it really is an eyeopener. It is a book I wished that I had read right in the beginning of starting to consider trading myself.
While not necessarily for trading, it’s helpful to have a broad selection of different types of knowledge in your latticework of the mind as Charlie Munger calls it. In case you didn’t know, Charlie Munger is Warren Buffet’s right hand man at Berkshire Hathaway.
Investing , the last liberal art by Robert G. Hagstrom
This table of contents is what got my attention with this book. I was a bit caught of guard at first with the topics and the connection they might make to investing. But, a short skim confirmed the author was right on target with all of the topics covered.
Table of Contents: Investing: The last Liberal Art
I didn’t know what to think of this book when I first saw it. But, it’s different from most investing books in a good way. It’s more about building a mindset, a latticework in your mind to pull from to better think about investing. Clearly, knowing other subjects beyond economics and finance are helpful to have a background of general knowledge to be able to pull ideas from. For me, I agree as this has been my own experience. This book went from one that I was skeptical about to a favorite after a few chapters.Initially the chapter titles caught my attention, as they were unlike any ones that I have seen in other investing books.
Principles of Economics by Alfred Marshall
Originally from 1890, it’s a classic. It’s still used in some college curriculums today. This book can provide a background on economics. With trading, you need to be able to understand the view from above as well. Understanding how economics works provides a high altitude view from far above the landscape of fundamentals and technical analysis. It’s important to a least have some understanding of the bigger picture, a macro view of economics from the beginning when you trade.
This is the 8th edition of what is regarded to be the first “modern” economics textbook, leading in various editions from the 19th into the 20th century. The final 8th edition was Marshall’s most-used and most-cited.
There are many thousands of people who buy and sell stocks speculatively but the number of those who speculate profitably is small. As the public always is “in” the market to some extent, it follows that there are losses by the public all the time. The speculator’s deadly enemies are: Ignorance, greed, fear and hope. All the statute books in the world and all the rules of all the Exchanges on earth cannot eliminate these from the human animal. Accidents which knock carefully conceived plans skyhigh also are beyond regulation by bodies of coldblooded economists or warm-hearted philanthropists.– Reminiscences of a Stock Operator
Trading Resource Videos
The following post contains video resources. Some of this material especially the material from Francis Hunt and David Paul on the psychology and mindset of trading is quite important. It is best to learn about the psychology and mindset of trading while learning other typical trading topics such as technical analysis and fundamentals. It is just as important in the long run and having discipline and the right mindset goes a long way to preventing losses and maximizing gains over the long haul.
Channels
Josh Olszewicz: Crypto + Technical Analysis, Building your trading toolbelt
Josh Olszewicz produces market updates on a regular basis cover BTC and ETH primarily. Plenty to learn from and in my opinion, reliable insights.
Francis Hunt produces periodic crypto market updates and actually trades in legacy markets as well and provides useful insights from both realms and also currencies plus gold and silver.
Aswath Damodaran: Fundamentals and Value Investing in Stocks.
He is a professor, so get ready to study. Many videos on his channel. A few updates here and there but , most of it is in depth college level training on topics such as valuation and analyzing the fundamentals of companies. Good information for a background on the stock market. Plenty of videos to pick and choose from as you want to dive into a specific topic.
Basics. Well done videos, most of them nice and short and covering specific topics. Everything that applies to spreadbetting can be applied to trading as well so don’t let the name fool you.
Francis Hunt Interview Series on UK Spread Betting
Especially these two in the series are very important… Trading Secrets of the Mind Master the Emotional Side of Trading Improving the Mindset Game in our Trading
Asset above 89 day MA. Market above 21 day MA And rising , will get hit rate to 80 Probability matrix Pattern to finesse entry . 1-2 pct at risk per trade. Plan and repeated perfect execution. Build neural pathways after 8-30 trades…….. William O’Neil How to make money in stocks……from The Psychology of trading and investing
Audio book: Trading For a Living, Psychology,Trading Tactics, Money Management
Not trading information specifically but, he is a legend. Mathematician, code breaker turned trading genius. He co-founded Renaissance Technologies in East Setauket, New York, a town away from where I grew up. Renaissance Technologies, Ren Tech, makes huge yearly gains in it’s Medallion Fund. The company does a lot of quant work and hires PhD scientists, mathematicians and etc. Working for this company would be amazing to say the least. So much to learn there working with the talented people he has helped to pick and shape over the years.
Renaissance’s flagship Medallion fund, which is run mostly for fund employees,[8] is famed for the best track record on Wall Street, returning more than 66 percent annualized before fees and 39 percent after fees over a 30-year span from 1988 to 2018.[9][10]
I got this example originally called simple-strat.py from a Datacamp article . I have my changes to the code up on Github.
Tunable DMAC
Basically the modifications to the original code incorporates a Dual Moving Average Crossover (DMAC) strategy that adjusts the averages to pick optimum values . DMAC is a very basic trend trading strategy. Other types of strategies would include, mean reversion, hedging such as pairs trading, arbitrage or buying and selling across the bid-ask spread as a market maker, so called earning the spread.
DMAC Basics
A dual moving crossover is exactly what the name says. There are two moving averages, one short and one long. When the short one rises above the long one, it is a buy signal. When they cross the other way, guess what, sell. This is almost about as dirt simple as a strategy can get. Single moving average, where price crosses one average would be the simplest moving average strategy. DMAC used in the example is not fancy at all, no stops, no screening, no failure mode protections. I have found that about 10% of designing a good algorithmic strategy is in the strategy, another 10-20% is in the tuning and generalizing, backtesting. The rest is protecting the strategy from itself, such as screening out bad trades. The absolute worst is price shocks, which can’t be predicted.
Tuning
Initially it was coded to work with stocks but, I revised it to take in BTC instead. I also took it one level up and had it automatically tune for the best combinations of the short and long average for the DMAC stratagy. This is a bit better than sitting there and fiddling the parameters by hand. The pitfall is that the model can be overfit to the backtest data and then perform poorly on new data. It is best to have a model that generalizes a bit. Sometimes this can be accomplished by actually dumbing the process down a bit or using a stochastic approach. More parameters in the model the more likely overfit will occur as well.
Aside on Ensemble Backtesting
One approach that I typically use when tuning an algorithmic models parameters is to use an ensemble approach. I have used this successfully with genetic algos, such as differential evolution. I will have the backtest tuning take random slices of the time series from random points within the time series. From this I will run backtests on each one and then average the results together to form the ensemble. This helps to generalize but, won’t work for every kind of model. This has to do with the nature of local maxima and minima that the model might rise up to or fall into. With some models averaging may just average to the plain and not the peaks and valleys. This has to be looked at carefully. But, I am getting off topic here.
DMAC versus Buy and Hold
The idea here is to do some Monday morning quarterbacking. When I was in industry this was always a thing on Mondays. No matter what the sport, everyone threw around the coulda, woulda, shouldas. Probably more so if there was money riding on the game. Well if you are a trader or investor, there is real money riding on the game so sometimes it is worth looking back and seeing how a trading strategy would have worked against the classic long term buy and hold. a.k.a HODL…hold on for dear life.
If any of the terminology or details above seem fuzzy, check out the Datacamp article.
Fantasy Account
If we bought BTC on 1/1/2019 and sold on 12/31/2019 and had a magic wand to make the perfect DMAC tuned model, would we have done better than buy and hold?
We start with $100K on 1/1/2019 and cash out on 12/31. What do we have?
DMAC with a 29 day short and 59 day long average…
Short AVG,Long AVG,Best Bank 29 59 902908.9599609375
$900K, the clear winner.
Buy and Hold comes in at $182K
HODL Gains: 1.8258754145331861
Obviously, this is perfect trades, like a Carnot cycle engine without friction, it’s not realistic . In the real world there are fees, slippages, price shocks, picking bad parameters and other gotchas.
But, even if you threw a dart at pairs of numbers for the averages, at least for 2019, odds are the DMAC would have beat buy and hold for the year. This is not always the case, as in years past a buy and hold would have beat the DMAC. See the printout here for a 2010-2017 run.
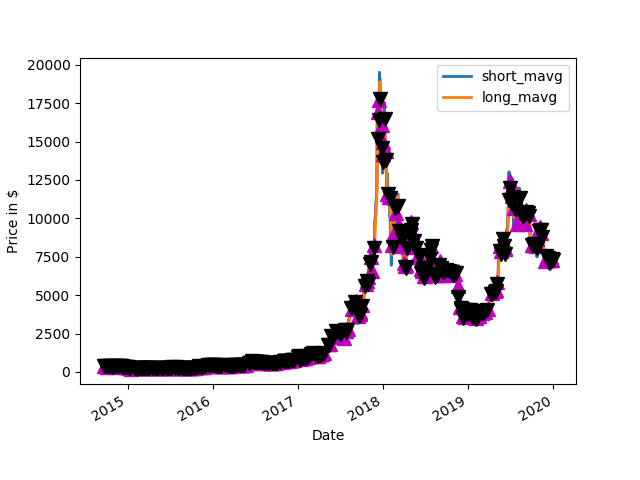
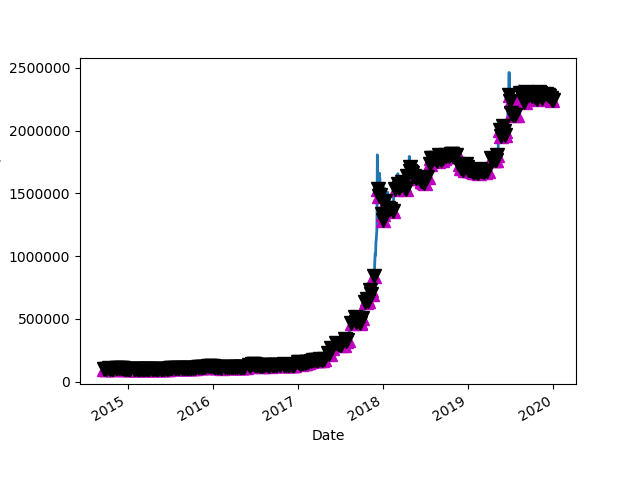
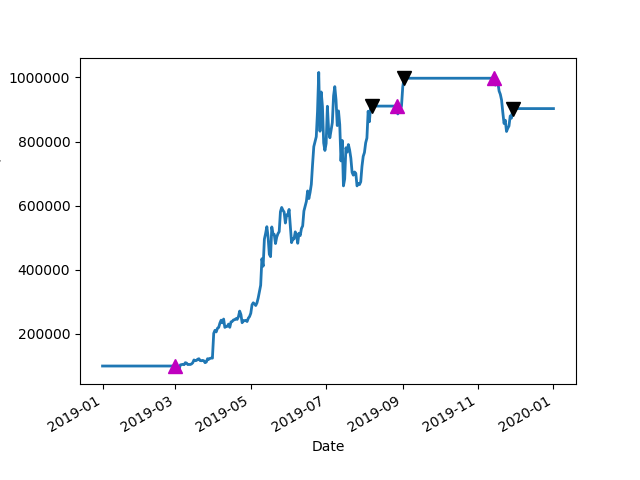
2019 BTC Price with Average and Buy and Sell points Up Arrow = BUY, Down Arrow = SELL2019: Amount of cash made on paper
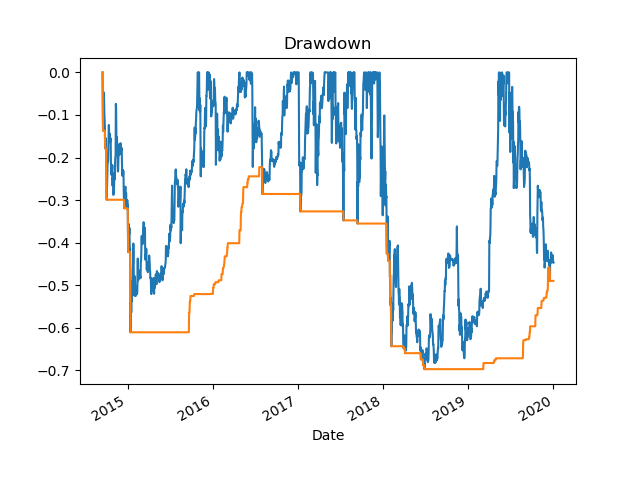
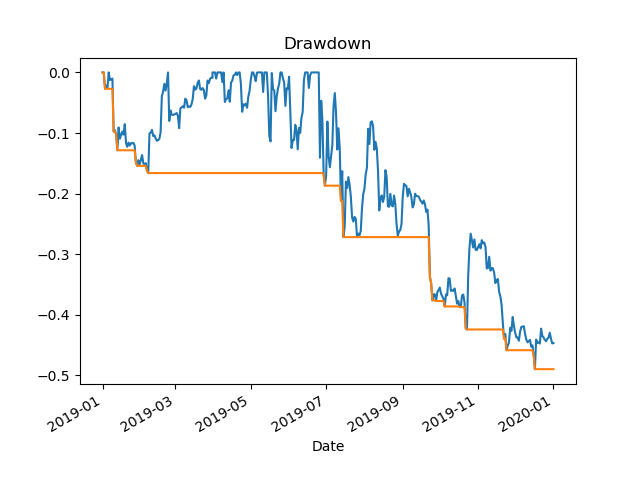
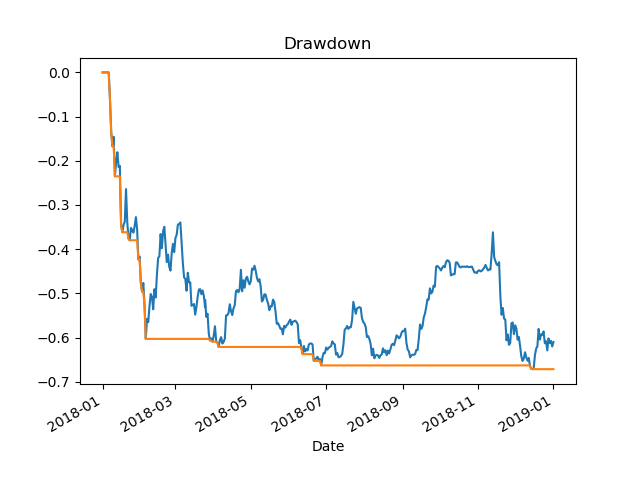
Maximum Drawdown for the Period 1/1/2019-12/31/2019
2018
Followup, I was curious about the rough 2018 year for BTC. 2018 was quite bearish, with only a few small rallies up. It had awful buy and hold performance.
HODL Gains: 0.2565408133534354
Short AVG,Long AVG,Best Bank 1 4 498855.46875
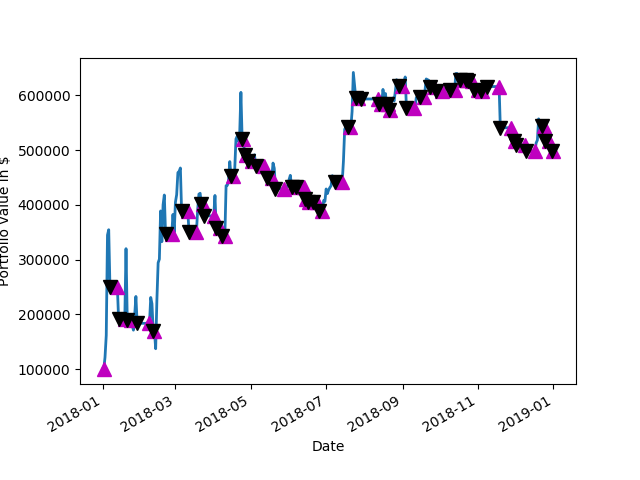
Buy and hold would have been a 4x loss and DMAC would have traded in and out quite often, racking up some fees and slippage of course but, made a 5X gain.
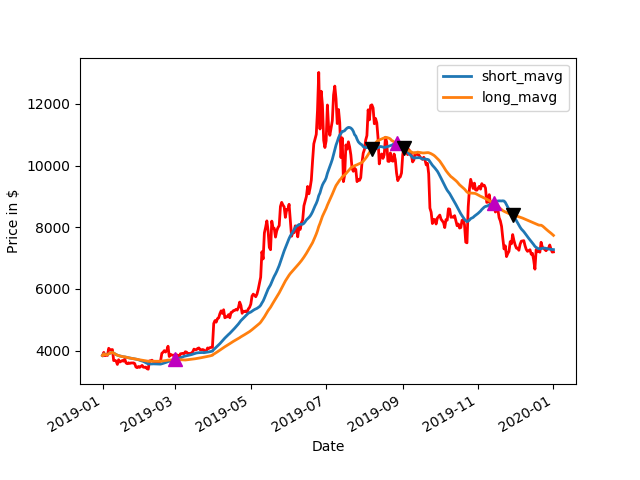
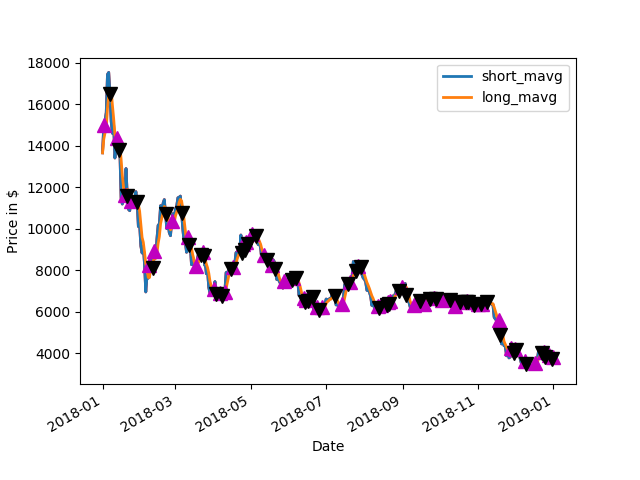
2018 BTC Price with Average and Buy and Sell points Up Arrow = BUY, Down Arrow = SELL2018: Amount of cash made on paper2018 Drawdown
This post covers code that I have played with that applies a style to an image. The code is derived from Siraj Raval’s work. I was interested in having a version that would run outside of a Python Jupyter notebook. The idea is to have a version that can be run from the command line. This allows for it to be run ‘production’ style. This means have it set with images and parameters and run right from the command line. I found a way to convert the code from Jupyter notebook code to straight Python. The exact method I can’t remember right now. The code also produces intermediate frames while running, one per iteration. These are stored in the itersdirectory. They can be used to monitor the models progress and optionally generate an animated GIF showing the unfolding of the process.
I have conda installed on my machine, so the dependency aka, requirements text file was used to load dependencies, following setup of the environment. This virtual environment makes sure that there are no collisions with other code environments, including the base. I did not want to upset anything that I depend on over an experiment. It can also be put under a virtual environment in Python. This is not a requirement but, good practice when developing code. It helps to keep the code in its own confined space and makes things work in a repeatable way. Making it easy to replicate the work of others in a controlled way. Sometimes it helps to be able to troubleshoot issues by switching between environments too.
Bear in mind that bigger resolution values will take longer than small. The memory requirements increase fast with resolution increases. I was only able to run 256 resolution on a machine with 4GB. I also tried to make thumbnail size images but, the model seems to have issues with smaller images, it produced distorted results. With a machine that has 16GB of RAM, it was easy to create 512 and 1024 pixel square images. When in doubt, monitor memory usage via the top command. The giveaway is swap gets used heavily with a large image. Even with a decent SSD and it having swap mounted on it, a machine might grind down to terrible lags in response, if swap is used dynamically on a heavy basis . Then the option is just to kill the process and make sure RAM is de allocated. This is really the only issue with running this code, memory use. If you have enough, it’s load up the dependencies and go.
It is currently ‘live’. What I mean by that is that it is a symlink to the working directory on my main machine that is rsync’d ( rsync options -avhLK) to it’s location online. So, it is subject to change, you may see things get added in, I may break links accidentally too, hopefully not. If something is obviously broken, shout out in a comment and I can fix it. I might eventually load code to Github as a static repository.
Note the images directory. Also under it is the styles directory. I have added a few more examples beyond what Siraj Raval had. Mostly downloaded from 4chan while scrolling through wallpaper and some random images that were collected on my machine from wherever. Plus a few that I made for doing references against a simple image, such as a red dot , red and black dot and grid lines.
Plain is a directory that contains the original Siraj Raval code for reference.
Images and styles, contain a sampling of images to try. In the code the image location for initial image and style image are hard coded. Look around line 37 to line 52 for…
content_image_path
and
style_image_path
and you will see examples that can be switched in and out via mask commenting the lines out. Change it as needed.Plus try your own for fun.
Adjust parameters if needed. Look for them around line 152 under the line with …
# In[51]:
Also around line 305 is the iterations variable which can be adjusted.
There are some samples of output that were generated in the top level directory. This is where the output is dumped as output.png. I just kept renaming the interesting images to useful names as I kept playing with various image and style combinations. You have to rename output.png as it will be overwritten when a new run occurs. It is possible to run rm ??output.png to delete them. It is possible to put this line in the script and activate. It is in the script but I have it commented out because I did not want to blast all of the output.png’s away when the gif is made.
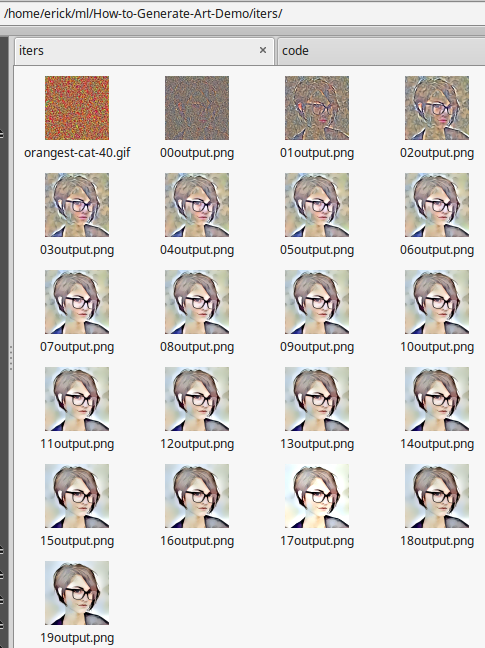
iters directory contains animated gifs of the images and a BASH script that is used to make the animated gifs.
notes.txt was a sketch of of the names for the virtual environment and conda environment, setups on two different machines. I might add other info and issues I find in this file.
Example of styling an image
Real 3D Person 512×512 as input from images/animeAnime 2D Person for the styling image, from images/style/anime
To get my bearings straight on this code again, I ran an example to make sure I understand it, it still runs. Hopefully others can gain insight into what a proper run does.
Input Images
Above I have two images, one the initial image and the second the style. The initial and styling image are both cropped to be 512×512 pixels, re-scaling as needed. Re-scaling is not necessary, except for the fact that the program will re-scale and if the proportions are not square, the resultant image will be stretched or squished.
On the first one there was a bit of a haze of blue to the right that I bucket filled to white so it wouldn’t get styled as well. From extending the photo to a larger canvas to make square this blue haze was an obvious line of demarcation. Plus her shoulder was truncated, so I filled that in a bit to make things look better. The anime image for styling was just cropped square and re-scaled too and flipped. Not sure if it makes a difference but, I looked for images that were close-ish in look and pose and set the same orientation.
Memory Usage and Performance
My machine, an i5, Sandy Bridge OptiPlex-790, can be see taking around 500-700 seconds per epoch. It was also running other code at the time, tuning parameters for algo trading code, so all the cores were not focused on making the images. Plus, all the miscellaneous stuff running, mail, browser with too many tabs open, it is using 1/2 core just doing that. But, 20 loops through the code is not a long time, really. You can see below that a fair amount of memory is being used, including some swap. But, the machine is not slowing down at all. I think some of the swap is just used up on other things and may not have been de-allocated over time, so it’s more or less static swap now.
While this code is running it will be copying png’s of the process into the iters directory. This lets you get a peek into the models progress and it is possible to use these later in conjunction with the make-gif-.sh in that directory to make an animated GIF of the model ‘building’ the final image. The copies starting from 00output.png and so on up to the last epoch number (The prefixing and order matter for the script to generate an animation) are a clue as to if things are going right. If after a few images, things look way off base or you question what direction the results are going, viewing the intermediate images give you a chance to abort early. There is a line in the file at the end that will optionally remove the output.png’s using rm ??output.png.
Iters Directory Showing Intermediate Copies
Command Line Output
From my command line this is what I see when it runs. Change to the directory, activate conda environment for the art-demo and fire off python demo-512.py. (I created another called demo-512-anime+human.py to replicate the example in this post ) Soon it spins up, well the fans on the machine do as well, Python grabs all the CPU power it can on all available cores so soon you will hear the power of machine learning as the fans kick to max RPM. Time goes by as the iterations of epochs run, 20 in this case. As long as the very high loss value is coming down, work is being done. As can be seen there is a point of diminishing returns beyond which not much is to be gained. This also can be assessed by looking at the progression of images in the iters directory. After it runs, it quits and a final output.png will appear in the top level, for me the ~/ml/How-to-Generate-Art-Demo/ directory, same directory the code is run from. Nothing special about ~/ml other than it is the place I keep all the machine learning code.
Note the warnings: I did not notice this right away but the Tensorflow install was not compiled to use SSE3,4.X and AVX. I retried a few loops of this example at 256×256 in my base install where Tensorflow seems to be compiled with these features and it yields 40% speed improvement.
(base) erick@OptiPlex-790 ~ $ cd ~/ml/How-to-Generate-Art-Demo/
(base) erick@OptiPlex-790 ~/ml/How-to-Generate-Art-Demo $ conda activate art-demo
(art-demo) erick@OptiPlex-790 ~/ml/How-to-Generate-Art-Demo $ python demo-512.py
Using TensorFlow backend.
(1, 512, 512, 3)
(1, 512, 512, 3)
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE3 instructions, but these are available on your machine and could speed up CPU computations.
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.1 instructions, but these are available on your machine and could speed up CPU computations.
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations.
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations.
Start of iteration 0
Current loss value: 1.68822e+11
Iteration 0 completed in 511s
Start of iteration 1
Current loss value: 1.05267e+11
Iteration 1 completed in 480s
Start of iteration 2
Current loss value: 7.54607e+10
Iteration 2 completed in 459s
Start of iteration 3
Current loss value: 5.67734e+10
Iteration 3 completed in 489s
Start of iteration 4
Current loss value: 4.71848e+10
Iteration 4 completed in 518s
Start of iteration 5
Current loss value: 4.19099e+10
Iteration 5 completed in 513s
Start of iteration 6
Current loss value: 3.82277e+10
Iteration 6 completed in 533s
Start of iteration 7
Current loss value: 3.56423e+10
Iteration 7 completed in 508s
Start of iteration 8
Current loss value: 3.36591e+10
Iteration 8 completed in 498s
Start of iteration 9
Current loss value: 3.21125e+10
Iteration 9 completed in 441s
Start of iteration 10
Current loss value: 3.08934e+10
Iteration 10 completed in 610s
Start of iteration 11
Current loss value: 2.9882e+10
Iteration 11 completed in 516s
Start of iteration 12
Current loss value: 2.90331e+10
Iteration 12 completed in 495s
Start of iteration 13
Current loss value: 2.82984e+10
Iteration 13 completed in 499s
Start of iteration 14
Current loss value: 2.76652e+10
Iteration 14 completed in 495s
Start of iteration 15
Current loss value: 2.70985e+10
Iteration 15 completed in 530s
Start of iteration 16
Current loss value: 2.66107e+10
Iteration 16 completed in 86288s
Start of iteration 17
Current loss value: 2.61579e+10
Iteration 17 completed in 526s
Start of iteration 18
Current loss value: 2.57533e+10
Iteration 18 completed in 642s
Start of iteration 19
Current loss value: 2.53972e+10
Iteration 19 completed in 717s
(art-demo) erick@OptiPlex-790 ~/ml/How-to-Generate-Art-Demo $
The output file appears in the same directory
(art-demo) erick@OptiPlex-790 ~/ml/How-to-Generate-Art-Demo $ ls output.png
output.png
Final Result
Final after 20 iterations Human + Anime (style image) = Humanime?
Animated GIF
To make an animated GIF from the output files in the iters directory. (Note, in Linux the program Convert must be installed if it is not already installed in the distribution that is being used). Go to the iters directory, make sure that there are no extraneous output.png files from previous runs. This can happen if a previous run was made that was longer, more iterations and generated numbered outputs above the last iteration. Then run…
In a few seconds a file called animation.gif will appear. Rename the file if you want to keep it as any future work may write over it.
The code is well commented and easy to tweak, thanks to Siraj Raval. I will end with one part of the conclusion , it’s appropriate as a final word.
# It's now your turn to play! Try changing the input images, their sizes, the weights of the different loss functions, the features used to construct them and enjoy different sorts of output. If you end up creating something you truly wish to share, [please do so](https://twitter.com/copingbear)!
Resources
Original work is on GitHub provided by Siraj Raval