
This post covers a trading algorithm developed in Python code that uses Fibonacci numbers to set levels to trade off of. It is not a short term strategy, however it is a long-term strategy more of an investment strategy. It is based on a post by Philip Swift on https://www.lookintobitcoin.com/charts/golden-ratio-multiplier/
And he also has an original article on it on medium.
I have code for this here:
https://github.com/erickclasen/cbpro-cli-tools
Theory
The golden ratio multiplier is a great indicator, visually easy to confirm and makes a lot of sense on how it works. Best of all no fussy back-testing with parameter tweaks, you just need your eyes. I like how Josh Olszewicz added the centerline, that is a nice addition. His video was a pleasant and positive surprise that I used to review the working of the golden ratio multiplier. I started using this indicator in early 2020.
On top of the basics that are covered by Phillip Swift , I have made some additions to the it that will work well in algorithmic form to allow it to run with constraints as code. Constraints are needed to allow it to pick the correct points to enter and exit along the curve. The method of (Dollar Cost Averaging) DCAing in and out is to use 20SMA BBands (Bollenger Bands) as a point to trigger DCA, using this as a filter to trigger on price exceeding lower/upper BBand. This tweak is based on the fact that I wrote code around this and was looking for a good way for when it should reasonably DCA, versus just triggering on a crossing the Fib # * YearlySMA (SMA, Simple Moving Average), or DCAing daily when under/above this line. As far as amounts to DCA, generally with accumulate/distribute investing, I tend to compound the trades in a way that accumulates heavier as distance increases below the YearlySMA line and distributes heavier as it goes further above the target Fib # * YearlySMA. The trading scaler used is a logistic curve , with n being the ratio of the current price to the yearly avg for buys (For sales ‘n’ is inverted by n being subtracted from the target Fib level multiplier + 1, which positions the curve out to where it scales up until it reaches the next higher Fib # and back down. Using the logistic curve formula (1+k)/(k + n^e) as a trade multiplier, for example with k=0.2 and e=4, it DCA’s in around 2x at the 0.8 * yearlySMA point,, 4x at 0.5…never more than 6x as it approaches that as a limit as n –> 0. I am planning publishing this code and documentation around it and will cite your video in it when I do.
Golden Ratio Multiplier Tutorial
Also Josh Olszewicz has a video tutorial on YouTube about this particular indicator using it with TradingView code it is a worth taking me 10 minutes or so to review this as background material along with looking at https://www.lookintobitcoin.com/charts/golden-ratio-multiplier/ and the original medium article . I am going to try to stick to the essence of the code and not so much the background material which could be read in viewed in those locations.
Code
This code is light weight and can be run on a Raspberry Pi as well as a Linux PC. It requires Python 3 as this is needed for the API.
The code is designed to use the Coin Base Pro API, however there is a middle layer that interfaces with the API via cbpro_buy_sell.py If someone wants to interface with another API this just needs to be modified to make the proper calls into another exchange as an API on the back end of it. Think of it as a thin interface layer that goes between the code and the API itself.
https://github.com/erickclasen/cbpro-cli-tools
Dependancy : One import
this would be the import cbpro code that constitutes the module for the CV pro interface API.
Other Internal Dependancies
There are a few dependencies in the code thankfully they are local dependencies. The intent was to make this code as freestanding as possible without having to import various library’s other than what is barely necessary to make it operate. The first is a file called coretamodule.py. It holds a lot of functions that are used in multiple algorithm some of which will be used in the code to implement the golden ratio multiplier which is known as the arc just Python. The other necessary dependency is a piece of code that calls for polls periodically the CB pro ticker to add prices and volumes to aC SV file. This is run from some thing like Cron on a regular basis hourly daily five minutes what have you it is run at the same rate as a fib-ad high is run calling this code 1st to fill in the CSV file which will be read in by fib active high. I will try to make this publicly available on a site where it could be pulled down with that lease this up to the current days data. Current days data
Core concepts
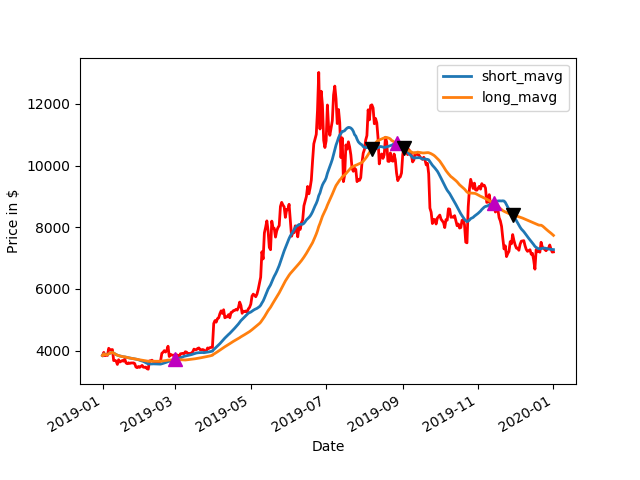
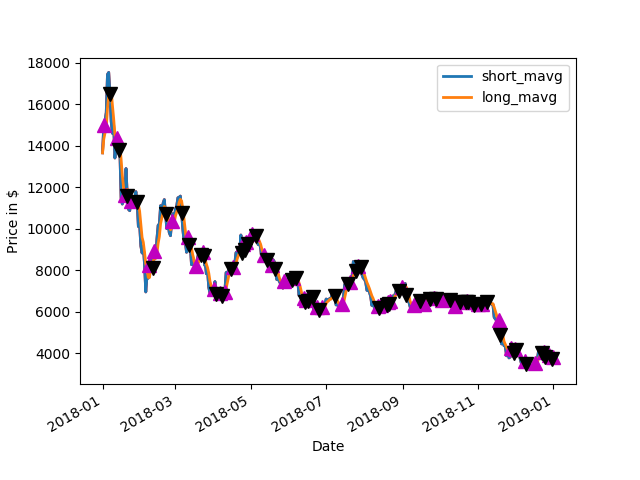
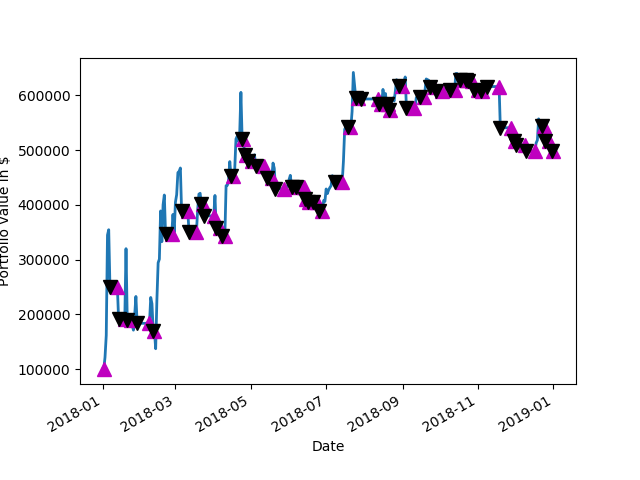
The idea of the code is that a 350 day moving average is calculated.This forms the basis of the ratio that is the golden ratio between the average and the price itself. When the price is below a threshold which is coded in to a dictionary of two pools as one. When below this level it will accumulate in the particular currency pair. There is another number in this threshold when it is above this ratio of price to 350 day moving average price. this forms the basis of the ratio that is the golden ratio between the average and the price itself. When the price is below a threshold which is coded in to a dictionary of tuples as one. When below this level it will accumulate in the particular currency pair. There is another number in this threshold when it is above this ratio of price to 350 day moving average price.above this range it will distribute the currency pair. Some fine tuning is made when it is above or below the threshold. The fine-tuning is based on Bollinger bands when it is touching the bottom bands in the Bollinger band 20 day bands and the minimum price for the 20 day period is also the same as this the price they buy is initiated.C onversely for the sale when the price is at the upper edge of the Bollinger band and the maximum price for the 20 day. Has been hit as a target a sale is initiated. This makes it dollar cost average in and out on a periodic basis. The idea is to have extra filtering to kind of find a peek in the valley of price movement without DCA (Dollar Cost Average) in too much or out too much.
defines.py
there is also a dependency file called defines.py this file has the portfolio amount in it. Now it is being dynamically allocated by using the cbpro_read_accts.py. It will scale the amount of USD traded however BTC an ETH have to be adjusted within the main function to pick values that are comfortable and proper for the trading circumstances. This allows for configuration between all of the pairs.Also in the defines file you will have to enter the key passphrase and be 64 secret, this will allow the trades to occur through the API as this is passed on by the main code.
Also in the defines file you will have to enter the key passphrase and be 64 secret, this will allow the trades to occur through the API as this is passed on by the main code.
Outputs and Logs
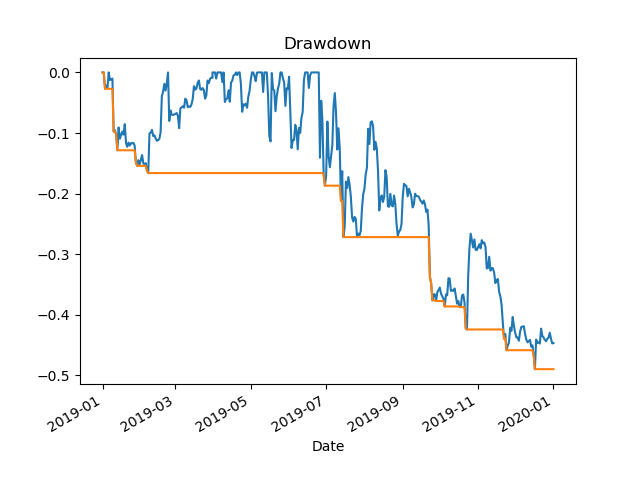
The output from the code is interpret able humanly to understand what is going on as well. There are rose of prices after the initial currency pairs listed these prices represent the various thresholds at the end it states whether it is holding or not and also what the threshold and target are the threshold being the Bollinger bands edge and the target being the lowest to highest price for the 28th time.Additionally there are log files created when the code runs there are several that are verbose and specific to a underlying currency and there is one summary file. The verbose files contain the returned output from the API function call which is a dictionary of values return from CB pro. There will also appear within the non-verbose output as a message usually relates to some thing that needs to be corrected possibly a bug or some thing like insufficient funds. This is driven by the message key from the CB Pro API return dictionary.
The code makes every attempt to avoid this because it uses limit orders and it also checks the balances in the supply. The underlying currency and the to be bought or sold currency itself.
Compounding Positions
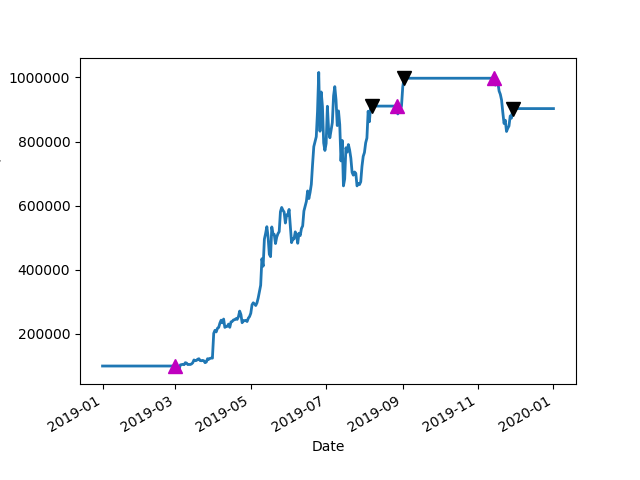
There is also a logistic scaler in this code. The logistics scaler works by increasing the amount of currency bought when the price falls below the threshold of the golden ratio multiplier which is by default one. This allows increasing the amount purchased automatically but also reaches a limit as the ratio between the price and the 350 day moving average approaches zero. It will go to a limiting constant. The opposite is true for cells there is the threshold that is coded into the dictionary of tuples the logistic scaler takes in that value plus one informs a curve that goes from the upper threshold to all 1+ this value and increases the amount sold after this plus one position it will decrease once again to zero. The idea is that it scales out hard as the price rises but has a limiting factor if it rises above the threshold too far. The idea would be to manually address these thresholds to what is expected of the currency. So periodically maintenance might be required on the threshold or they might just be a set it and forget it for some people. This all depends on how you want to invest.
As the price rises but has a limiting factor if it rises above the threshold too far. The idea would be to manually address these thresholds to what is expected of the currency. So periodically maintenance might be required on the threshold or they might just be a set it and forget it for some people. This all depends on how you want to invest.The default or one and two in a two pole for every currency pair. It is possible to adjust days as needed. It is also possible to adjust the logistics scaler Constants which are KNEE is the exponential constant which controls the rate of rise of the curve and key controls the multiplier affect in the amount that would be traded in the limit.
Outer Loop
The code works by looping through a list actually a dictionary of underlying currencies US D/ETH/BTC as underlyings. Then there is a function call and the inner currencies are called in a loop these other currencies that are actually traded against the underlying currencies. This allows money currency pairs to be traded and others to be added in the future.
CSV Data Collection using API
The caveat here is that there has to be enough data in the CSV file to go back for the time. And if a currency one is to be added it has to be attitude there to harvest the ticker data. I suppose in theory it would be possible to fit all data into the file itself to add a prior prior currency that’s been running in the ticker for a while if someone is motivated not to do that. Having this code in a folder and having it called by Cron preferably using a script calling the script first then harvesting the price volume data then calling for code it will work seamlessly as a plug and play algorithm. Because it is using the golden ratio multiplier there is no need for back testing as this has been proven out to work by Philip Smith Swift in his presentation and write up online.
Obviously this code could be modified in anyway the 350 day. Could be changed to something else along with the 20 day Bollinger band. And the threshold as I said earlier our configurable.






{kind=link}
{kind=link}