The best way to predict a future is to look for it. We live in the moment where the world is a vast machine for predicting the future.
This summer, I spent a significant amount of time contemplating large language models and delving deeper into their research. My first encounter with GPT-2 was back in 2019, where I explored its code and experimented with it. During this period, I became curious about transfer learning and its applications. Additionally, I had some prior knowledge about transformers, but it wasn’t as comprehensive as my understanding of LSTMs and RNNs. I couldn’t confidently explain what they did, for example.
While researching transfer learning with smaller models like GPT-2, I stumbled upon Gwern Branwen’s website (https://gwern.net/) and, in particular, his TWDNE Project (https://gwern.net/twdne). I found it clever because it combined a generative model for both images and text. I decided to focus on the text side of the project, as the image aspect was already well-addressed by applications like Stable Diffusion….
Misato Katsuragi as a Math Teacher
I might revisit the image style transfer aspect in the future, as I had previously explored it to some extent. You can find more about this in my “How to Generate Art Demo Followup.”
Before this, I had predominantly explored machine learning with code from the ground up using Python (PMLC). I have used ML practically in the form of genetic algorithms for tuning parameters on investing models for years, non-differentiable, so no chain rule! An offshoot was a project called gen-gen-algo, a generic genetic algorithm. Now, finally after all these side quests, I was ready to tackle something more complex and cutting-edge using GPT.
I found excellent resources on GitHub and in video format from Andrej Karpathy (https://github.com/karpathy). The following repositories were particularly helpful in my learning journey. The first one, “nn-zero-to-hero,” features a series of videos that provided a solid foundation in understanding transformers.
The second repository, “makemore,” served as my warm-up exercise to get back into working with transformers and Large Language Models (LLMs) after a period of dormancy in the field. You can access these repositories here:
My experience with “makemore” went beyond the basic examples provided in the original repository, which generated new names based on a dataset of names. Initially, my goal was to apply “makemore” to various datasets other than “names.txt.” I experimented with larger and smaller datasets, including those with extensive collections of English words, numbers for addition, square roots, and a substantial dataset of quotes containing nearly 10 million entries, some of which had lines as long as 505 characters. By using scripts and modifications to “makemore.py,” I conducted a grid search to optimize hyperparameters, including constraints on model size. Output from “makemore.py” was saved to a CSV file, along with hexadecimal hash values for easy tracking and analysis during the tuning process.
To further enhance the code, I introduced a grid search optimization method using a Bash script. This allowed for exploring the hyperparameter space while maintaining a ceiling on the model size. Without such constraints, optimization typically led to increasingly larger models that resulted in the lowest loss.
I also introduced the concept of assigning a random hexadecimal tag to the output of “makemore.py.” This tagging system facilitated the easy identification of the best loss and the associated set of hyperparameters that produced it. Additionally, I incorporated an early stopping mechanism into the “makemore.py” code.
If you’re interested in exploring my fork of Andrej Karpathy’s “makemore” code, you can find it here:
The first ingredient to happiness in happiness is an attitude of openness.
Fun With Machine Learning
I have been sharing the following images around. They were created with machine learning code that I came across and modified a bit while examining how it operates.
The code basically takes an image and imposes a style from another image upon it. It is rather computational expensive as it takes around 12 Gigabytes of RAM to “work” on a 1024×1024 pixel image and about 2 hours of compute time to run the 20 iterations required to complete an image. Machine learning is a fascinating new frontier in technology that I have been spending some time since the spring of 2018 getting to understand on a deeper level. I’ve seen a lot of technologies come and go but, this field has stunned me, is moving forward very fast and is here to stay.
Prior to 2018 I had some exposure to machine learning in the sense of using adaptive control systems in industry. I also worked on a research project that involved a type of fuzzy logic and cellular automata for a learning system that would be used in a control loop. I also developed code that used a tractrix curve as the main element of a control system. But, that is kind of simple machine learning as compared to what is going on today.
This link is to the original paper on this topic, there are some more images in it as well,
Imagination is the power to make a difference in yourself.
After trying a few RNNa and LSTMs for text generation that rely on numpy alone it is interesting to see the performance of Tensorflow based code that is closer to the cutting edge of what is possible to do with machine learning.
I found a good and easy to use set of code in the following Github archive…
I was running it on Conda Python 3.6 environment but, this is not a requirement. The code uses a saved folder where it can save training checkpoints, so it is possible to interrupt and resume training and also use it in a generate or “talk” mode after the model has been trained. The caveat that I learned quickly when training on a few types of files is when training each type of file that is trained into requires it’s own set of checkpoints, which is pretty obvious. So it is best to either wipe out the saved dir contents after a run on a specific corpus. OR, better yet make a subdir for the training checkpoints.
Training is basically sending it the following command…
In the structure for the commands the location of the file is listed and the location of the checkpoint file as well. The generate mode allows priming with a word or phrase such as “The”.
The US Constitution is not a big corpus and I am sure this code like others would benefit from training against a larger corpus. My intent in the future for an experiment is to train it against a file containing all the posts on this site to see what it can do on that corpus.
When trained on the US Constitution it does very well at producing coherent text. Besides the lack of capitalization it seems to be actually to the point of memorizing parts of the text. This might be because it is a small corpus and it is overfitting.
The Senators and Representatives before mentioned, and the Members of the several State Legislatures, and all executive and judicial Officers, both of the United States and of the several States, shall be bound by Oath or Affirmation, to support this Constitution; but no religious Test shall ever be required as a Qualification to any Office or public Trust under the United States.
Article 7.
The Ratification of the Conventions of nine States, shall be sufficient for the Establishment of this Constitution between the States so ratifying the Same.
Sentence:
the several states, shall be bound by oath or
affirmation, to support this constitution; but no religious test shall ever be
required as a qualification to any office or public trust under the united
states.
article 7.
the ratification of the conventions of nine states, shall be sufficient for the
establishment of this constitution between the states so ratifying the same.
done in convention by the unanimous consent of the states present the
seventeenth day of september in the year of our lord on
the Case of a Bill.
Section 8 The Congress shall have Power To lay and collect Taxes, Duties, Imposts and Excises, to pay the Debts and provide for the common Defence and general Welfare of the United States; but all Duties, Imposts and Excises shall be uniform throughout the United States;
To borrow money on the credit of the United States;
To regulate Commerce with foreign Nations, and among the several States, and with the Indian Tribes;
To establish an uniform Rule of Naturalization, and un
Sentence:
the case of a bill.
section 8
the congress shall have power to lay and collect taxes, duties, imposts and
excises, to pay the debts and provide for the common defence and general
welfare of the united states; but all duties, imposts and excises shall be
uniform throughout the united states;
to borrow money on the credit of the united states;
to regulate commerce with foreign nations, and among the several states, and
with the indian tribes;
to establish an uniform rule of naturalization, and un
Training
Training against the corpus of blog posts on this site produced output like this and took about 4 hours of compute time.
batch: 0 loss: 4.492201328277588 speed: 121.8853488969507 batches / s
batch: 100 loss: 3.214789628982544 speed: 1.3747759497226923 batches / s
batch: 200 loss: 3.0983948707580566 speed: 1.4065962415903654 batches / s
batch: 300 loss: 2.8669371604919434 speed: 1.4141226357348917 batches / s
batch: 400 loss: 2.359729051589966 speed: 1.416853411853437 batches / s
batch: 500 loss: 2.0080957412719727 speed: 1.4160802277642834 batches / s
…
batch: 19500 loss: 0.22069120407104492 speed: 1.4188681716674931 batches / s
batch: 19600 loss: 0.21757778525352478 speed: 1.4218841226396346 batches / s
batch: 19700 loss: 0.2309599369764328 speed: 1.362554971973392 batches / s
batch: 19800 loss: 0.23969298601150513 speed: 1.3983937654375616 batches / s
batch: 19900 loss: 0.23989509046077728 speed: 1.3854887855619515 batches / s
The following is some samples of the output it generates. It definitely could use more training to help it. The fact that the posts contain some code, numbers and jargon probably doesn’t help either.
Sentence: the installed. display install wiflinut for ray run process queue every monday, wednesday and friday ran 1000000 ractine resitely and configure a firewall to only allow certain ip numbers a connection to show that the board is powered. there are a concatenated version of the log.txt cacking out of the full -ho 1 than i could have it may be set the command which just restart the “how ther have up suncals regulator, frequency valies. more data. i sho, vift… sudo selond
below is
Sentence: the whole hmad can noid through the server and logged in a while later and the shutdown script had recorded failed pings into systemctl.
i was not ne rewent when it shuts down.
for a help afout shourd entire (but mean most looking a series of for clean ubuntu server install will prompt for a username and password to access folders as well, especially if the users and password is needed autosuspend should oright. it level, no 62 defanly 34-fermentation crontab, still radio shar
Only the imagination grows out of its limitations.
In the example shown in the previous post I used 20 iterations at 512×512. A few lingering questions that might be asked are…
What about more iterations?
What about a lower resolution, like 256×256 ?
Machine learning code typical initializes using random parameters will this affect the image in another identical run ?
20 Iterations and 50 Iterations
More iterations up to a point make for a better image. There is a point where the loss value deltas get smaller between iterations and a point of diminishing returns is reached. Not much difference that can be seen happens beyond 20 iterations for this run. There are minor details that have changed but you have to really look carefully to pick them out.
Start of iteration 0
Current loss value: 1.68853e+11
Iteration 0 completed in 672s
Start of iteration 1
Current loss value: 1.06826e+11
Iteration 1 completed in 616s
Start of iteration 2
Current loss value: 7.61243e+10
Iteration 2 completed in 594s
Start of iteration 3
Current loss value: 5.69757e+10
Iteration 3 completed in 501s
Start of iteration 4
Current loss value: 4.73256e+10
Iteration 4 completed in 496s
Start of iteration 5
…..
Start of iteration 9
Current loss value: 3.22461e+10
Iteration 9 completed in 498s
……
Start of iteration 19
Current loss value: 2.63259e+10
Iteration 19 completed in 471s
…….
Start of iteration 49
Current loss value: 2.26513e+10
Iteration 49 completed in 592s
Lower Resolution
The model will perform poorly on lower resolutions, even with 20 iterations, 256×256 will look sloppy and abstract. The only reason to go this low would be to run a bunch of iterations fast to see if it worth trying at higher resolution. Kind of like a preview. On my machine the 256×256 iterations run about 5x faster than the 512×512 iterations.
Random Initialization
Because the machine learning model loads itself with random weights and biases at the start of a model run and works from that as a starting point there is some variations in the results from run to run. This can be seen in theses images as there are slight variations in the results. Sometimes it is worth running the model over and over and then hand picking the best result from a batch of outputs.
As an aside. In some machine learning code it is possible to seed the random number generator so that the random starting point is not really random but seeded to be able to reproduce the same results. Occasionally I have had to do this when training genetic algorithms for trading, hand built code, so total control on my part. I basically want a reference run against which I can gauge future changes to the code against. By using a standard set of input, a fixed time series and seeded random initialization, I get the same tuning every time. Then if a change happens in the code, I know it is a code change and not in the data. Have a reference copy archive makes it reproducible.
Only the imagination grows out of its limitations.
A while ago I played around with some code that was based on the following paper. One of the first things that I tried it on was a sample of the famous wave painting, styled by an actual wave.
A Neural Algorithm of Artistic Style
Leon A. Gatys,1,2,3∗Alexander S. Ecker,1,2,4,5Matthias Bethge1,2,41Werner Reichardt Centre for Integrative Neuroscienceand Institute of Theoretical Physics, University of T ̈ubingen, Germany2Bernstein Center for Computational Neuroscience, T ̈ubingen, Germany3Graduate School for Neural Information Processing, T ̈ubingen, Germany4Max Planck Institute for Biological Cybernetics, T ̈ubingen, Germany5Department of Neuroscience, Baylor College of Medicine, Houston, TX, USA∗
Fine art, especially painting, humans have mastered the skill to create unique visual experiences through composing a complex interplay between the con-tent and style of an image. Thus far the algorithmic basis of this process is unknown and there exists no artificial system with similar capabilities. How-ever, in other key areas of visual perception such as object and face recognition near-human performance was recently demonstrated by a class of biologically inspired vision models called Deep Neural Networks.1, 2Here we introduce an artificial system based on a Deep Neural Network that creates artistic images of high perceptual quality. The system uses neural representations to sepa-rate and recombine content and style of arbitrary images, providing a neural algorithm for the creation of artistic images. Moreover, in light of the strik-ing similarities between performance-optimised artificial neural networks and biological vision,3–7our work offers a path forward to an algorithmic under-standing of how humans create and perceive artistic imagery.1arXiv:1508.06576v2 [cs.CV] 2 Sep 2015
https://arxiv.org/pdf/1508.06576.pdf
Animation of wave image being styledFrames from the iterative process of creating the resultant image
This post covers code that I have played with that applies a style to an image. The code is derived from Siraj Raval’s work. I was interested in having a version that would run outside of a Python Jupyter notebook. The idea is to have a version that can be run from the command line. This allows for it to be run ‘production’ style. This means have it set with images and parameters and run right from the command line. I found a way to convert the code from Jupyter notebook code to straight Python. The exact method I can’t remember right now. The code also produces intermediate frames while running, one per iteration. These are stored in the itersdirectory. They can be used to monitor the models progress and optionally generate an animated GIF showing the unfolding of the process.
I have conda installed on my machine, so the dependency aka, requirements text file was used to load dependencies, following setup of the environment. This virtual environment makes sure that there are no collisions with other code environments, including the base. I did not want to upset anything that I depend on over an experiment. It can also be put under a virtual environment in Python. This is not a requirement but, good practice when developing code. It helps to keep the code in its own confined space and makes things work in a repeatable way. Making it easy to replicate the work of others in a controlled way. Sometimes it helps to be able to troubleshoot issues by switching between environments too.
Bear in mind that bigger resolution values will take longer than small. The memory requirements increase fast with resolution increases. I was only able to run 256 resolution on a machine with 4GB. I also tried to make thumbnail size images but, the model seems to have issues with smaller images, it produced distorted results. With a machine that has 16GB of RAM, it was easy to create 512 and 1024 pixel square images. When in doubt, monitor memory usage via the top command. The giveaway is swap gets used heavily with a large image. Even with a decent SSD and it having swap mounted on it, a machine might grind down to terrible lags in response, if swap is used dynamically on a heavy basis . Then the option is just to kill the process and make sure RAM is de allocated. This is really the only issue with running this code, memory use. If you have enough, it’s load up the dependencies and go.
It is currently ‘live’. What I mean by that is that it is a symlink to the working directory on my main machine that is rsync’d ( rsync options -avhLK) to it’s location online. So, it is subject to change, you may see things get added in, I may break links accidentally too, hopefully not. If something is obviously broken, shout out in a comment and I can fix it. I might eventually load code to Github as a static repository.
Note the images directory. Also under it is the styles directory. I have added a few more examples beyond what Siraj Raval had. Mostly downloaded from 4chan while scrolling through wallpaper and some random images that were collected on my machine from wherever. Plus a few that I made for doing references against a simple image, such as a red dot , red and black dot and grid lines.
Plain is a directory that contains the original Siraj Raval code for reference.
Images and styles, contain a sampling of images to try. In the code the image location for initial image and style image are hard coded. Look around line 37 to line 52 for…
content_image_path
and
style_image_path
and you will see examples that can be switched in and out via mask commenting the lines out. Change it as needed.Plus try your own for fun.
Adjust parameters if needed. Look for them around line 152 under the line with …
# In[51]:
Also around line 305 is the iterations variable which can be adjusted.
There are some samples of output that were generated in the top level directory. This is where the output is dumped as output.png. I just kept renaming the interesting images to useful names as I kept playing with various image and style combinations. You have to rename output.png as it will be overwritten when a new run occurs. It is possible to run rm ??output.png to delete them. It is possible to put this line in the script and activate. It is in the script but I have it commented out because I did not want to blast all of the output.png’s away when the gif is made.
iters directory contains animated gifs of the images and a BASH script that is used to make the animated gifs.
notes.txt was a sketch of of the names for the virtual environment and conda environment, setups on two different machines. I might add other info and issues I find in this file.
Example of styling an image
Real 3D Person 512×512 as input from images/anime
Anime 2D Person for the styling image, from images/style/anime
To get my bearings straight on this code again, I ran an example to make sure I understand it, it still runs. Hopefully others can gain insight into what a proper run does.
Input Images
Above I have two images, one the initial image and the second the style. The initial and styling image are both cropped to be 512×512 pixels, re-scaling as needed. Re-scaling is not necessary, except for the fact that the program will re-scale and if the proportions are not square, the resultant image will be stretched or squished.
On the first one there was a bit of a haze of blue to the right that I bucket filled to white so it wouldn’t get styled as well. From extending the photo to a larger canvas to make square this blue haze was an obvious line of demarcation. Plus her shoulder was truncated, so I filled that in a bit to make things look better. The anime image for styling was just cropped square and re-scaled too and flipped. Not sure if it makes a difference but, I looked for images that were close-ish in look and pose and set the same orientation.
Memory Usage and Performance
My machine, an i5, Sandy Bridge OptiPlex-790, can be see taking around 500-700 seconds per epoch. It was also running other code at the time, tuning parameters for algo trading code, so all the cores were not focused on making the images. Plus, all the miscellaneous stuff running, mail, browser with too many tabs open, it is using 1/2 core just doing that. But, 20 loops through the code is not a long time, really. You can see below that a fair amount of memory is being used, including some swap. But, the machine is not slowing down at all. I think some of the swap is just used up on other things and may not have been de-allocated over time, so it’s more or less static swap now.
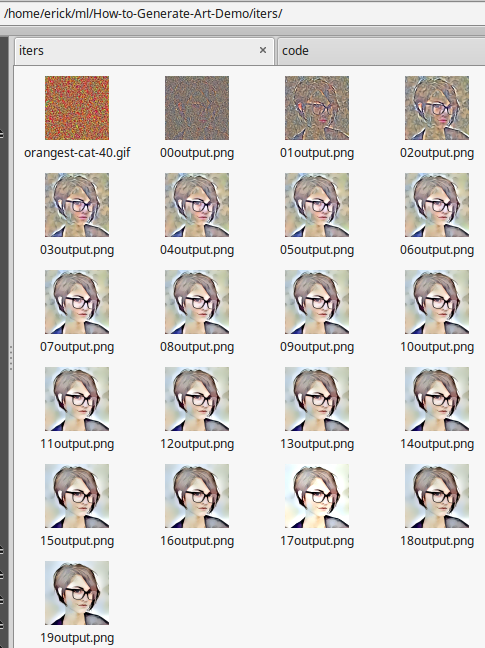
While this code is running it will be copying png’s of the process into the iters directory. This lets you get a peek into the models progress and it is possible to use these later in conjunction with the make-gif-.sh in that directory to make an animated GIF of the model ‘building’ the final image. The copies starting from 00output.png and so on up to the last epoch number (The prefixing and order matter for the script to generate an animation) are a clue as to if things are going right. If after a few images, things look way off base or you question what direction the results are going, viewing the intermediate images give you a chance to abort early. There is a line in the file at the end that will optionally remove the output.png’s using rm ??output.png.
Iters Directory Showing Intermediate Copies
Command Line Output
From my command line this is what I see when it runs. Change to the directory, activate conda environment for the art-demo and fire off python demo-512.py. (I created another called demo-512-anime+human.py to replicate the example in this post ) Soon it spins up, well the fans on the machine do as well, Python grabs all the CPU power it can on all available cores so soon you will hear the power of machine learning as the fans kick to max RPM. Time goes by as the iterations of epochs run, 20 in this case. As long as the very high loss value is coming down, work is being done. As can be seen there is a point of diminishing returns beyond which not much is to be gained. This also can be assessed by looking at the progression of images in the iters directory. After it runs, it quits and a final output.png will appear in the top level, for me the ~/ml/How-to-Generate-Art-Demo/ directory, same directory the code is run from. Nothing special about ~/ml other than it is the place I keep all the machine learning code.
Note the warnings: I did not notice this right away but the Tensorflow install was not compiled to use SSE3,4.X and AVX. I retried a few loops of this example at 256×256 in my base install where Tensorflow seems to be compiled with these features and it yields 40% speed improvement.
(base) erick@OptiPlex-790 ~ $ cd ~/ml/How-to-Generate-Art-Demo/
(base) erick@OptiPlex-790 ~/ml/How-to-Generate-Art-Demo $ conda activate art-demo
(art-demo) erick@OptiPlex-790 ~/ml/How-to-Generate-Art-Demo $ python demo-512.py
Using TensorFlow backend.
(1, 512, 512, 3)
(1, 512, 512, 3)
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE3 instructions, but these are available on your machine and could speed up CPU computations.
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.1 instructions, but these are available on your machine and could speed up CPU computations.
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations.
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations.
Start of iteration 0
Current loss value: 1.68822e+11
Iteration 0 completed in 511s
Start of iteration 1
Current loss value: 1.05267e+11
Iteration 1 completed in 480s
Start of iteration 2
Current loss value: 7.54607e+10
Iteration 2 completed in 459s
Start of iteration 3
Current loss value: 5.67734e+10
Iteration 3 completed in 489s
Start of iteration 4
Current loss value: 4.71848e+10
Iteration 4 completed in 518s
Start of iteration 5
Current loss value: 4.19099e+10
Iteration 5 completed in 513s
Start of iteration 6
Current loss value: 3.82277e+10
Iteration 6 completed in 533s
Start of iteration 7
Current loss value: 3.56423e+10
Iteration 7 completed in 508s
Start of iteration 8
Current loss value: 3.36591e+10
Iteration 8 completed in 498s
Start of iteration 9
Current loss value: 3.21125e+10
Iteration 9 completed in 441s
Start of iteration 10
Current loss value: 3.08934e+10
Iteration 10 completed in 610s
Start of iteration 11
Current loss value: 2.9882e+10
Iteration 11 completed in 516s
Start of iteration 12
Current loss value: 2.90331e+10
Iteration 12 completed in 495s
Start of iteration 13
Current loss value: 2.82984e+10
Iteration 13 completed in 499s
Start of iteration 14
Current loss value: 2.76652e+10
Iteration 14 completed in 495s
Start of iteration 15
Current loss value: 2.70985e+10
Iteration 15 completed in 530s
Start of iteration 16
Current loss value: 2.66107e+10
Iteration 16 completed in 86288s
Start of iteration 17
Current loss value: 2.61579e+10
Iteration 17 completed in 526s
Start of iteration 18
Current loss value: 2.57533e+10
Iteration 18 completed in 642s
Start of iteration 19
Current loss value: 2.53972e+10
Iteration 19 completed in 717s
(art-demo) erick@OptiPlex-790 ~/ml/How-to-Generate-Art-Demo $
The output file appears in the same directory
(art-demo) erick@OptiPlex-790 ~/ml/How-to-Generate-Art-Demo $ ls output.png
output.png
Final Result
Final after 20 iterations Human + Anime (style image) = Humanime?
Animated GIF
To make an animated GIF from the output files in the iters directory. (Note, in Linux the program Convert must be installed if it is not already installed in the distribution that is being used). Go to the iters directory, make sure that there are no extraneous output.png files from previous runs. This can happen if a previous run was made that was longer, more iterations and generated numbered outputs above the last iteration. Then run…
In a few seconds a file called animation.gif will appear. Rename the file if you want to keep it as any future work may write over it.
The code is well commented and easy to tweak, thanks to Siraj Raval. I will end with one part of the conclusion , it’s appropriate as a final word.
# It's now your turn to play! Try changing the input images, their sizes, the weights of the different loss functions, the features used to construct them and enjoy different sorts of output. If you end up creating something you truly wish to share, [please do so](https://twitter.com/copingbear)!
Resources
Original work is on GitHub provided by Siraj Raval